Postgresql
Настройка производительности. Подбираем оптимальные конфиги
Автор: Давыденков Михаил
Содержание
- настройка сервера
- диски и файловые системы
- оптимизация БД и приложения
- бенчмарки базы
Для начала
Проверить версию, т.к. улучшения от версии к версии значительны
- 7e версии - появился журнал транзакций, неблокирующий VACUUM, подсистема статисткики, команда ANALYZE (гистограмма распределения данных в столбцах)
- 8е версии - автоматизирован pg_actovacuum, добавлено автоматическое использование индексов для некоторых аггрегирующих функций, полнотекстовый поиск, улучшение производительности ряда запросов
- 9е версии - репликация из коробки, новые типы данных и индексов, ускорена сортировка и ускорен доступ к памяти, Matview и общий прирост производительности
Не использовать настройки по умолчанию!
По умолчанию настройки для совместимости, а не для производительности (особенно память). Нужно учитывать:
- конфигурацию компьютера
- объём и тип хранимых данных
- соотношение числа запросов на чтение / запись
- запущены ли другие требовательные к ресурсам процессы
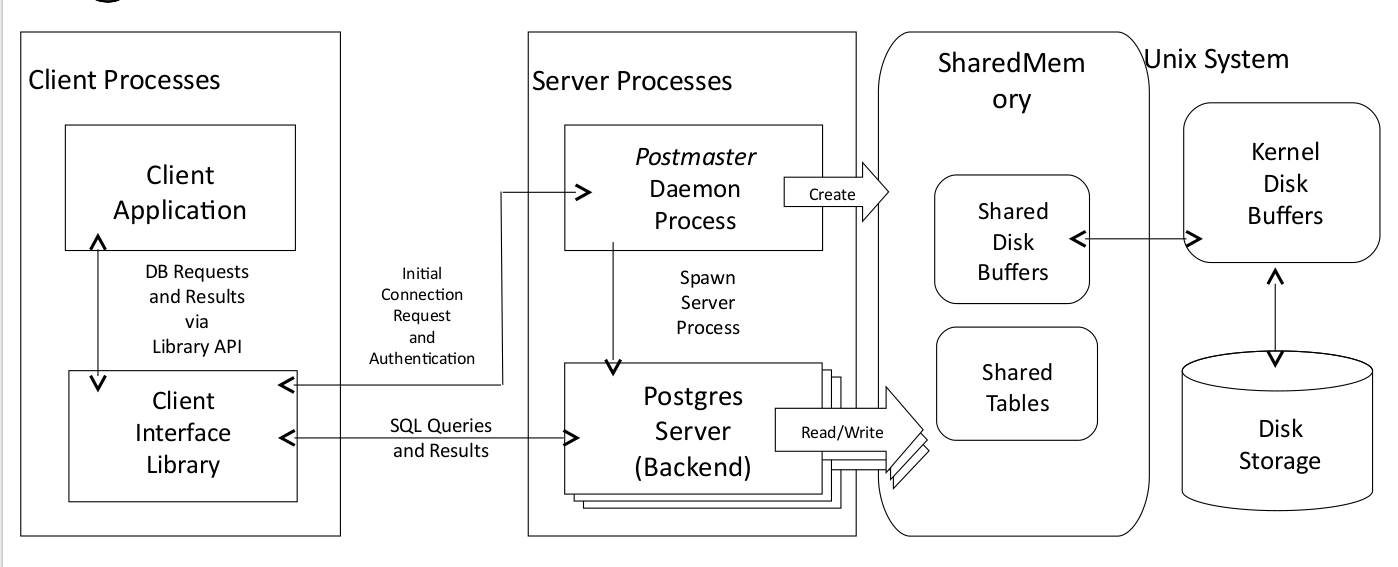
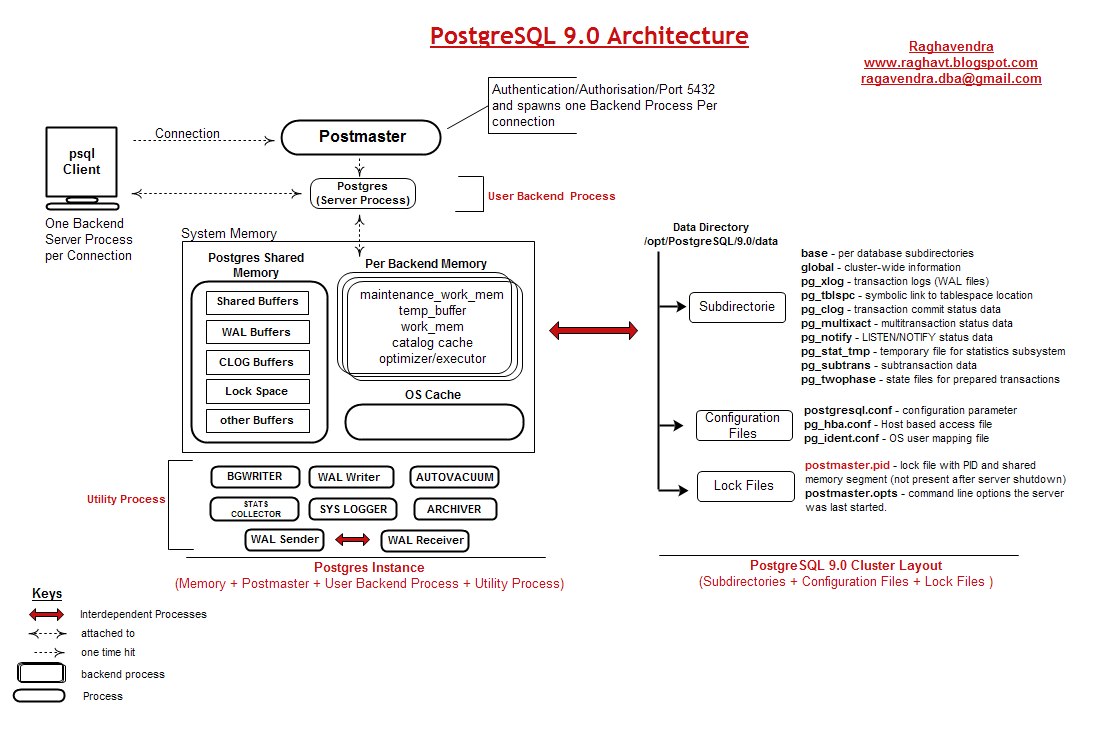
Настройка сервера
- используемая память
- журнал транзакций (WAL)
- планировщик запросов
- сбор статистики
Настройки памяти. shared buffers
совместно используемая память (разделяемая между процессами), выделяемая сервером postgresql для кэширования данных, определяется числом страниц (shared_buffers) по 8 килобайт каждая
1/4 - 1/8 ram, для более тонкой настройки можно воспользоваться pg_buffercache из contrib (проверяем закешированы ли наиболее популярные таблицы), а также утилитами ipcs, free или vmstat
Настройки памяти. shared buffers
# Запрос, показывающий использование буферов объектами
SELECT c.relname , count(*) AS buffers
FROM pg_buffercache b INNER JOIN pg_class c
ON b.relfilenode = pg_relation_filenode(c.oid) AND
b.reldatabase IN (0 , (SELECT oid FROM pg_database WHERE
datname = current_database()))
GROUP BY c.relname
ORDER BY 2 DESC
LIMIT 100;
# Запрос, показывающий таблицы/индексы в кэше с кол-вом использований
SELECT c.relname, count(*) AS buffers, usagecount
FROM pg_class c
INNER JOIN pg_buffercache b
ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d
ON (b.reldatabase = d.oid AND d.datname = current_database())
GROUP BY c.relname, usagecount
ORDER BY c.relname, usagecount;
# Запрос, который показывает какой процент общего буфера используют
обьекты (таблицы и индексы) и на сколько процентов объекты находятся
в самом кэше (буфере)
SELECT c.relname, pg_size_pretty(count(*) * 8192) as buffered,
round(100.0 * count(*) / (SELECT setting FROM pg_settings
WHERE name = 'shared_buffers')::integer, 1) AS buffers_percent,
round(100.0 * count(*) * 8192 / pg_table_size(c.oid), 1) AS percent_of_relation
FROM pg_class c
INNER JOIN pg_buffercache b
ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d
ON (b.reldatabase = d.oid AND d.datname = current_database())
GROUP BY c.oid , c.relname
ORDER BY 3 DESC
LIMIT 20;
Настройки памяти. shared buffers
Используя эти данные можно проанализировать для каких объектов не хватает памяти или какие из них потребляют основную часть общего буфера. На основе этих данных можно более правильно делать тюнинг shared_buffers параметра для PostgreSQL.
настройки памяти. work_mem
неразделяемая память (per backend), определяющая максимальное количество оперативной памяти, которое может быть затрачено на операцию (сортировка, аггрегация и тп.)
~1/25 RAM . Если объём памяти недостаточен для сортировки некоторого результата, то серверный процесс будет использовать временные файлы. Если же объём памяти слишком велик, то это может привести к своппингу.
настройки памяти. maintanance_work_mem
Этот параметр задаёт объём памяти, используемый командами VACUUM, ANALYZE, CREATE INDEX, и добавления внешних ключей
~1/4 RAM . От 50 до 75% размера вашей самой большой таблицы или индекса
настройки памяти. maintanance_work_mem
До версии 7.2 команда VACUUM полностью блокировала таблицу. Начиная с версии 7.2, команда VACUUM накладывает более слабую блоки ровку, позволяющую параллельно выполнять команды SELECT, INSERT, UPDATE и DELETE над обрабатываемой таблицей. Старый вариант команды называется теперь VACUUM FULL.
Новый вариант команды не пытается удалить все старые версии записей и, соответственно, уменьшить размер файла, содержащего таблицу, а лишь помечает занимаемое ими место как свободное
настройки памяти. прочие настройки
temp_buffers
Буфер под временные объекты, в основном для временных таблиц. Можно установить порядка 16 МБ
настройки памяти. прочие настройки
max_prepared_transactions
Количество одновременно подготавливаемых транзакций (PREPARED TRANSACTION). Можно оставить по дефолту — 5
настройки памяти. прочие настройки
vacuum_cost_delay
Если у вас большие таблицы, и производится много одновременных операций записи, вам может пригодиться функция, которая уменьшает затраты на I/O для VACUUM, растягивая его по времени. Чтобы включить эту функциональность, нужно поднять значение vacuum_cost_delay выше 0 (50 - 250 мс)
Для более тонкой настройки повышайте vacuum_cost_page_hit и понижайте vacuum_cost_page_limit . Это ослабит влияние VACUUM, увеличив время его выполнения. В тестах с параллельными транзакциями при значениях delay — 200, page_hit — 6 и page_limit —100 влияние VACUUM уменьшилось более чем на 80%, но его длительность увеличилась втрое
настройки памяти. прочие настройки
max_stack_depth
Специальный стек для сервера, в идеале он должен совпадать с размером стека, выставленном в ядре ОС (2-4 Мб).
Журнал транзакций (WAL)
Все изменения в файлах данных (в которых находятся таблицы и индексы) производятся только после того, как они были занесены в журнал транзакций, при этом записи в журнале должны быть гарантированно записаны на диск
контрольные точки
данные из буферов сбрасываются на диск при проходе контрольной точки: либо при заполнении нескольких (параметр checkpoint_segments , по умолчанию 3) сегментов журнала транзакций, либо через определённый интервал времени (параметр checkpoint_timeout , измеряется в секундах, по умолчанию 300).
Меняем параметры, если операции на запись тормозят
контрольные точки
Если в базу заносятся большие объёмы данных, то контрольные точки могут происходить слишком часто. При этом производительность упадёт из-за постоянного сбрасывания на диск данных из буфера.
- Можно выставить параметр checkpoint_warning == 60 (секунды)
- Увеличить checkpoint_segments (для веба рекомендуется 32)
- Размазать IO операции во времени, поставив checkpoint_completion_target - (0.7 - 0.9)
fsync и synchronous_commit
fsync OFF
Записи из журнала транзакций никогда не будут переносится на диск базой (вся тяжесть синхронизации write_buffers с диском ложится на плечи ОС). После сбоя проблемно восстановиться, т.к. неясно что из WAL синхронизовано, а что нет.
Не надо так делать, если дорожите данными. Но можно включить в девелопменте или в CI. (Связанный параметр full_page_writes)
fsync и synchronous_commit
synchronous_commit OFF
определяет нужно ли ждать WAL записи на диск перед возвратом успешного завершения транзакции для подключенного клиента
fsync call происходит, но не мгновенно после коммита после транзакции. Не рискуем крахом базы, но рискуем потерять несинхронизованные транзакции (ROLLBACK, если их не удалось синхронизовать)
http://dba.stackexchange.com/questions/18509/difference-between-fsync-and-synchronous-commit-postgresqlЖурнал транзакций. Прочее
commit_delay
Определяют задержку между попаданием записи в буфер журнала транзакций и сбросом её на диск. Если при успешном завершении транзакции активно не менее commit_siblings транзакций, то запись будет задержана на время commit_delay
Эти параметры позволят ускорить работу, если параллельно выполняется много «мелких» транзакций.
Журнал транзакций. Прочее
wal_sync_method
Метод, который используется для принудительной записи на диск. Зависит от ОС
- open_datasync
- fdatasync
- fsync_writethrough
- fsync
- open_sync
Журнал транзакций. Прочее
wal_buffers
Количество памяти, используемое в SHARED MEMORY для ведения транзакционных логов. Следует увеличить буфер, если требуется работать с большими транзакциями.
Планировщик запросов. default_statistics_target
Увеличение параметра заставит эту команду работать дольше, но может позволить оптимизатору строить более быстрые планы, используя полученные дополнительные данные
Планировщик запросов. effective_cache_size
На выделенном сервере имеет смысл выставлять effective_cache_size в 2/3 от всей оперативной памяти; на сервере с другими приложениями сначала нужно вычесть из всего объема RAM размер дискового кэша ОС и память, занятую остальными процессами.
Планировщик запросов. random_page_cost
Переменная, указывающая на условную стоимость индексного доступа к страницам данных. На серверах с быстрыми дисковыми массивами имеет смысл уменьшать изначальную настройку до 3.0, 2.5 или даже до 2.0. Если же активная часть вашей базы данных намного больше размеров оперативной памяти, попробуйте поднять значение параметра.
Понижаем, если больше seq scans, иначе - повышаем. Не ниже 2.0
Не помешает провести бенчмарки
Подсистема статистики. track_counts
Собирать или не собирать статистику?
Отключайте, если статистика вас не интересует, также как автовакуум (не делайте так!)
Подсистема статистики. track_functions
отслеживание использования определенных пользователем функций
Подсистема статистики. track_activities
Передавать ли сборщику статистики информацию о текущей выполняемой команде и времени начала её выполнения. По умолчанию эта возможность включена.
Следует отметить, что эта информация будет доступна только привилегированным пользователям и пользователям, от лица которых запущены команды, так что проблем с безопасностью быть не должно.
Диски и файловые системы
Тюнинг ОС для БД - предмет отдельного разговора, как и выбор файловой системы для БД. Но лучше использовать журналирующую ФС, чтобы быстро восстанавливаться после возможных сбоев.
Выйгрыш в производительности может легко быть получен если ФС примонтировать с параметром noatime (при этом не будет отслеживаться время последнего доступа к файлу, но нагрузка на диск снизится)
Диски и файловые системы
Перенос журнала транзакций на другой диск
При доступе к диску изрядное время занимает не только собственно чтение данных, но и перемещение магнитной головки. Данные пишутся в журнал транзакций последовательно и можно сэкономить время перетащив журнал транзакций на отдельный физический диск (например на маленький SSD)
Диски и файловые системы
Перенос журнала транзакций на другой диск
- Остановите сервер
- Перенесите каталоги pg_clog и pg_xlog на другой диск
- Создайте на старом месте символическую ссылку
- Запустите сервер
Команда CLUSTER
CLUSTER table [ USING index ] — команда для упорядочивания записей таблицы на диске согласно индексу, что иногда за счет уменьшения доступа к диску ускоряет выполнение запроса.
Возможно создать только один физический порядок в таблице, поэтому и таблица может иметь только один кластерный индекс. При таком условии нужно тщательно выбирать, какой индекс будет использоваться для кластерного индекса.
CLUSTER требует «ACCESS EXCLUSIVE» блокировку!
Оптимизация БД и приложения
- Сборка мусора, мешающего добраться до актуальных данных
- Наличие быстрого доступа к данным - индексов
- Возможность использования оптимизатором этих быстрых путей
- Обход известных проблем
Команда ANALYZE
Демон автовакуум уже вызывает команду ANALYZE, но может потребоваться вызывать её вручную, если известно что после изменения колонок "интересующая статистика не затронута"
Команда REINDEX
Команда REINDEX используется для перестройки существующих индексов. Использовать её имеет смысл в случае
- порча индекса
- постоянное увеличение размера индекса
Индекс, как и таблица, содержит блоки со старыми версиями записей. PostgreSQL не всегда может заново использовать эти блоки, и поэтому файл с индексом постепенно увеличивается в размерах. Если данные в таблице часто меняются, то расти он может весьма быстро.
REINDEX требует «ACCESS EXCLUSIVE» блокировку!
Использование нужных индексов
Поля, являющиеся внешними ключами, и поля, по которым объединяются таблицы, индексировать надо обязательно
Индексов должно быть достаточно:
- Команды, изменяющие данные в таблице, должны изменить также и индексы. Очевидно, чем больше индексов построено для таблицы, тем медленнее это будет происходить
- Оптимизатор перебирает возможные пути выполнения запросов. Если построено много ненужных индексов, то этот перебор будет идти дольше
Команда EXPLAIN
EXPLAIN показывает как будет выполняться запрос
EXPLAIN ANALYZE ещё и выполнит запрос, так что EXPLAIN ANALYZE DELETE не очень хорошая идея
Команда EXPLAIN
Чтение вывода этих команд - искусство, но для начала можно обращать внимание на следующее:
- Использование полного просмотра таблицы (seq scan)
- Использование наиболее примитивного способа объединения таблиц (nested loop)
Анализ собранной статистики
- pg_stat_user_tables - общее количество полных просмотров и просмотров с использованием индексов, общие количества записей, которые были возвращены в результате обоих типов просмотра, а также общие количества вставленных, изменённых и удалённых записей
- pg_stat_user_indexes - общее количество просмотров, использовавших этот индекс, количество прочитанных записей, количество успешно прочитанных записей в таблице (может быть меньше предыдущего значения, если в индексе есть записи, указывающие на устаревшие записи в таблице)
- pg_statio_user_tables - общее количество блоков, прочитанных из таблицы, количество блоков, оказавшихся при этом в буфере
Анализ собранной статистики
Из этих представлений можно узнать:
- Какие индексы вообще не используются в запросах. Их имеет смысл удалить
- Для каких таблиц стоит создать новые индексы (индикатором служит большое количество полных просмотров и большое количество прочитанных блоков)
- Достаточен ли объём буфера сервера
Больше сниппетов
Всегда полезны скрипты, автоматизирующие какие-то рутинные операции. Я начал собирать свою коллекцию сниппетов для postgres, присоединяйтесь! :)
Можно заглянуть сюда - https://github.com/DavydenkovM/postgres_snippets
psql -f 'snippet_name' -d database_name
Бенчмарки
Самое простое - использовать pgbench (contrib)
pgbench -i -s 1 -d database_name -U user_name
pgbench -d database_name
##
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
tps = 1897.173212 (including connections establishing)
tps = 2189.621196 (excluding connections establishing)
Бенчмарки
On top of pgbench - pgbench-tools (Py, shell, PlpgSQL, gnuplot)
https://github.com/gregs1104/pgbench-tools
createdb results
createdb pgbench
psql -f init/resultdb.sql -d results
./newset 'Initial Config'
./runset
##
Долго считает с разными вариантами нагрузки
В итоге выводит результаты и строит графики
Возможно нужно будет настроить pg_hba.conf
Бенчмарки
Требуют отдельного изучения (TPC-B является obsolete на данный момент, нужно изучить инструменты TPC-DS)
http://www.slideshare.net/fuzzycz/performance-archaeology-40583681Что дальше
Решение проблем чтения
- мультиплексоры соединений
- репликация (можно посмотреть в сторону гема makara)
- внедрение failover стратегий
- кэширование / репорты через MatView
- партицирование
Решение проблем записи
- партицирование
- системы очередей (PgQ, пакет skytools 2)
- шардинг (если больше нет вариантов)
- интеграция с NoSQL решениями через FDW например
- интеграция с брокерами сообщений